Publishing linked data is becoming easier, and we now come across new RDF datasets almost everyday. One question that keeps being asked however is “what can I do with it?” More or less everybody understand the general advantages of linked data, in terms data access, integration, mash-up, etc., but getting to know and use a particular dataset is far from trivial: “What does it say? What can I ask it?”
You can look at the ontology to get an idea of the data model used there, send a couple of SPARQL queries to `explore’ the data, look at example objects. etc. We also provide example SPARQL queries to help people getting the point of our datasets. Of course, not everybody is proficient enough in SPARQL, RDF-S and OWL to really get it using this sort of clues. Also, datasets might be heterogeneous in the representation of objects, in the distribution of values, or simply very big and broad.
To help people who don’t necessarily know/care about SPARQL `getting into’ a complex dataset, we developed a system (whatoask) that automatically extract a set of questions that a dataset is good at answering. The technical aspects of realising that are a tiny bit sophisticated (i.e., it uses formal concept analysis) and are detailed in a paper I will present next week at the K-CAP conference. What is interesting however is how such a technique can provide a navigation and querying interface of top of a linked dataset, providing a simple overview of the data and a way to drill down to particular areas of interest. In essence, it can be seen as an FAQ for a dataset, not presenting frequently asked questions, but the questions the dataset is specially good at answering.
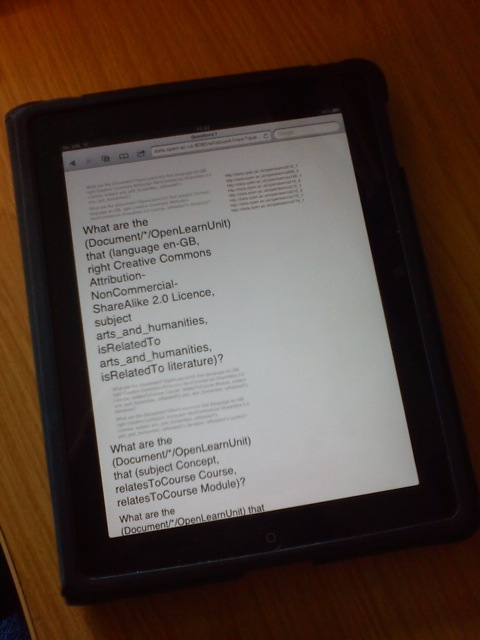
What the tool does is creating a hierarchy of all the simple questions an RDF dataset can answer, and presents to the user a subset that, according to a set of metrics described in the paper, are believed to be more likely of interest. The questions are displayed in a pseudo natural language, in a format where for example “What are the (Person/*) that (knows Tom) and that (KMi hasEmployee)?” can be interpreted as the question “What are the people who know Tom and are employed in KMi?”. Questions can be selected, and displayed with their answers, and the question hierarchy can be navigated, selecting more specific and more general questions than the selected one.
To clarify what that means, let’s look at what it does on the data.open.ac.uk OpenLearn dataset. The initial screen shows a list of questions, the first one (“What are the (Document/*/OpenLearnUnit) that (subject Concept, relatesToCourse Course, relatesToCourse Module)?”, i.e., “What are the OpenLearn Units that are related to courses and have a topic?”) being selected. More general and more specific questions are also shown, such as “What are the OpenLearn Units that have a topic?” (more general) and “What are the OpenLearn Units that relate to a course and have for topic `Education Research’?” (more specific).
We can select alternative questions, such as the second in the list — “What are the OpenLearn Units in english distributed under a creative commons licence and that talk about Science?”, obtain a new list of answers (quite a few), as well as more general and more specific questions. We can then specialise the question to “What are the OpenLearn Unit in english under a CC licence that talk about science and family?” and carry-on with a more general question looking at the `family topic’ without science, to finally ask “What are the OpenLearn units about family?” (independently of the licence and language).
As can be seen from the example, the system is not meant for people who know in advance what they want to ask, but to provide a level of serendipitous navigation amongst the queries the dataset can answer, with the goal of giving a general overview of what the dataset is about and what it can be used for. The same demo is also available using the set of reading experiences from the RED dataset and the datasets regarding buildings and places at the OU. The interface is not the most straightforward at the moment, but we are thinking about ways by which the functionalities of the system could be integrated in a more compelling manner, as a basic `presentation’ layer on top of a linked dataset.
Pingback
by Final Product Post: Tabloid « The LUCERO Project
01 Jul 2011 at 09:04
[...] What to ask Linked Data? – this describes a tool that extract from a dataset the questions it is particularly good at answering. A demo shows the tool applied on 3 datasets from data.open.ac.uk. [...]
by Mathieu
01 Jul 2011 at 13:54
the presentation for at the KCAP 2011 conference of the technique behind “whatoask” is now available online: http://www.slideshare.net/mdaquin/extracting-relevant-questions-to-an-rdf-dataset-using-formal-concept-analysis