Tabloid is a toolkit intended to help institutions and developers to both publish and consume linked data. It is a mixture of documentation explaining the why and how of linked data, and real examples of how linked data can be used including code, tools and documentation. The figure below gives an overview of the relationship between the different components of the toolkit.

Understanding Linked Data
The first step for institutions wishing to deploy and use linked data is to reach an adequate understanding of the its basic principles, of the technologies involved and of the potential benefits. In What is Linked Data?, we provide a high-level summary targeting both technical and non-technical people.
In summary, the very basic idea linked data is based on is that data, instead of staying in database management systems that are “interfaced” to the Web, are put directly on the Web, using the Web architecture. Every piece of data, every object or resource the data talks about, is identified by a Web address and data representation is realised through linking these Web adresses with each other, independently from where they are located and how they were created. This provides a model for naturally accessible and integrated data, in addition to a high level of flexibility that makes it possible to extend and enrich linked data incrementally, without having to reconsider the entire system: there is no system, only individual contributions.
Several of the applications we developed in LUCERO (see below) demonstrate some key elements of linked data, and how we can take benefit from it by reducing the cost of managing and using our own data, but more importantly, by creating new value out of the connections between previously isolated data. We are still very far from completely understanding what can be achieved with linked data. The simple principles it is based on open up to completely new ways to deal with data, to manage them and to use them.
Link: What is Linked Data?
Publishing Linked Data
The larger part of the process of integrating linked data in an institution is to publish as linked data information that originates from many different sources. There are many steps in this process, that we mainly see according to two aspects: the business process and the technical process.
The business process
Discussing with data owners, convincing them of the benefit of linked data, involving them in the process of re-modelling the data and helping them in engaging with linked data in their daily work, is probably where the biggest effort of setting up a linked data platform in an institution comes from. Based on our experience in LUCERO, we devised a common, very general set of steps and goals for such process, indicating the roles of the different participants in the process.
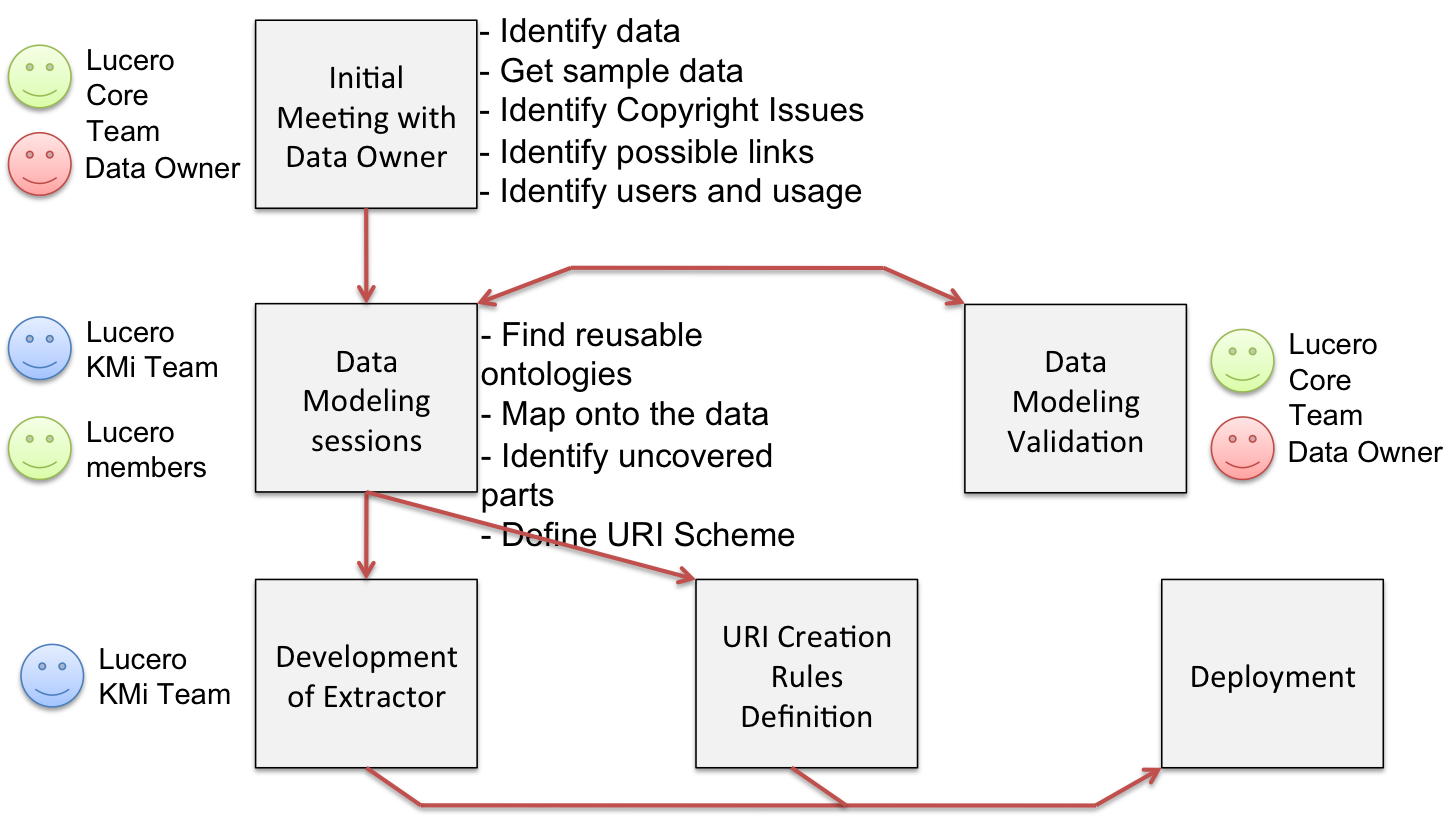
Applying this process to create a linked data platform such as data.open.ac.uk is not as straightforward as it might first appear: it can be very time consuming with results that are sometimes counter-intuitive. It is also a constant effort to keep in contact and agreement with the data owners. The presentation Experience from 10 months of University Linked Data (below) gives an overview of the lessons learnt through realising data.open.ac.uk.
Beyond the deployment of the linked data platform, the integration of linked data into the information management practices of the institution is a critical step, requiring adequate policies and workflows, as well as the engagement of the relevant members of staff and managers. This is the topic of an ongoing work with the information management team of the Open University library, who is in charge of devising and documenting these policies and workflows. The result of this work will be made available here very soon.
Link: The presentation Experience from 10 months of University Linked Data
The technical process
A large part of the technical development of a linked data platform consists of a set of tools to extract RDF from existing sources of data, load this RDF into a triple store and expose it through the Web. This might sound simple, but the reality is that, in order to achieve this with sources that are constantly changing and that are originally working in isolation requires a workflow which is at the same time efficient, flexible and reusable. The workflow used in LUCERO (which is generally reusable) is described in Initial overview of the LUCERO workflow and is depicted in the figure below.
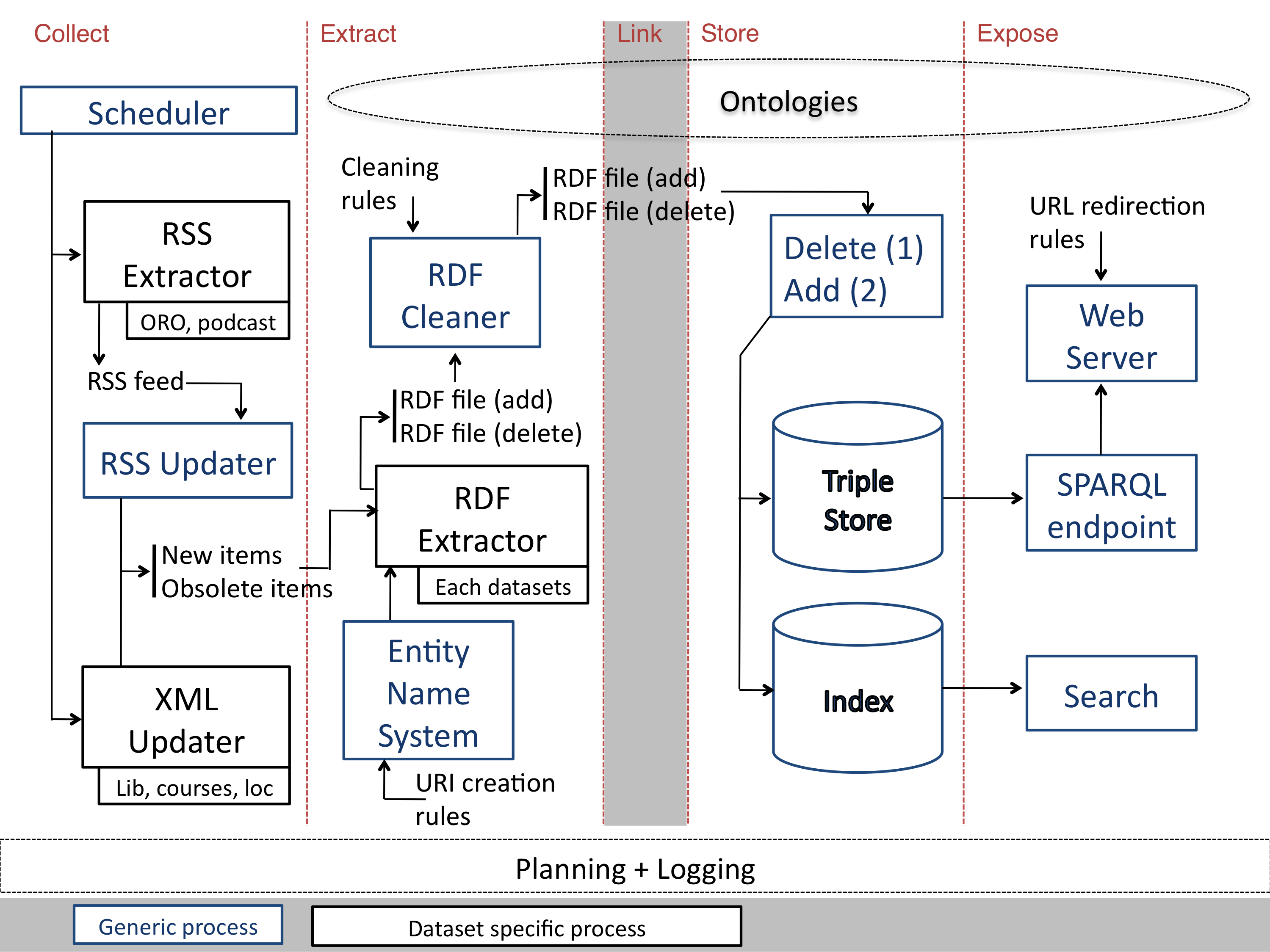
There are many possible choices for a triple store (e.g., Sesame, Jena, Vituoso, OWLIM) and many different ways to expose the data from such a triple store (e.g., through a SPARQL endpoint, resolvable URIs, linked data API). LUCERO uses OWLIM with the SPARQL endpoint provided by the Sesame interface. We implement our own code (see source code for URI delivery in LUCERO) to resolve URIs, using apache rewrite rules to achieve content negotiation (meaning that the request is redirected to RDF or HTML depending on the value of the “Accept” HTTP header).
One of the crucial points of the linked data architecture is the way updates are handled. Changes need to be detected at regular intervals and propagated to the RDF representation and to the triple store. Flexible and lightweight solutions should be preferred, in order to avoid adding linked data-specific tasks to the data owners and their systems.
A crucial element here concerns the way the different datasets connect to each other: through common URIs. Therefore a set of global rules need to be put in place regarding the way URIs are created for every type of objects that might be encountered in the source data, and these rules need to be integrated within the data extraction workflow of the linked data architecture. It is highly recommended to realise a general component (called the “Entity Name System” in LUCERO) to implement these rules.
Finally, at the basis of the linked data platform are a number of extractors specially dedicated to the source data being processed. Some tools used in institutional repositories include export mechanisms to RDF (e.g., Eprints) but generally require some level of cleaning and customisation (see Publishing ORO as linked data). Other sources of data provide generic interfaces or common formats across institutions. We developed in particular a tool called Youtube2RDF that extracts in an RDF format the playlists and the metadata about videos in a given Youtube Channel (often used by universities for educational and promotional material). We are also currently working on a tool to facilitate the re-modelling of course descriptions in the XCRI format into linked data. The result of this ongoing work will be added here. Finally, for institution-specific sources, ad-hoc extractors need to be realised. The LUCERO source code includes the extractors we developed on a number of sources, including RSS and XML feeds. These can be used as examples and adapted to other sources of data.
Link: Initial overview of the LUCERO workflow
Link: Source code for URI delivery
Link: Youtube2RDF
Link: LUCERO source code for extractors
Vocabularies and Ontologies
A large part of the effort regarding data modelling for linked data concerns the identification of the appropriate ontologies and RDF vocabularies to be used. This is a specially difficult task as it needs to take into account the existing data, and how well the chosen vocabularies can represent them, as well as the potential reuse and interoperability issues that the vocabularies could raise. Indeed, it is only through sharing common vocabularies and representation models that the data from different institutions can be used jointly and connect through linked data.
For this reason, we created the Linked Universities Portal with the goal to provide a place for people interested in University linked data to share common vocabularies, data, recipes and approaches. The Vocabularies page in particular already contains descriptions of vocabularies commonly used for course descriptions, organisational structures, publications and multimedia resources. These are the same vocabularies employed in LUCERO and examples from data.open.ac.uk are provided to illustrate the use of these vocabularies.
It is expected for Linked Universities to grow and contain more and more examples, as people from other institutions engage with it.
Link: Linked Universities
Link: Linked Universities Vocabularies
Consuming Linked Data
We believe that, just like for deploying a website, linked data can be exposed without any specific goal in mind. We publish linked data online with the idea that they can be reused and exploited by a large variety of applications, most of which were not intended originally. However, as part of integrating linked data in the institution’s practices, it is important to understand clearly how to work with linked data, how to make use of it and how to write applications that exploit the benefits of linked data in the institution’s context.
Background
The linked data platform of an institution can be a formidable resource for the institution itself, but will only achieve its potential if developers can make use of it to create new applications, or to make existing applications more efficient and less resources consuming (mainly in terms of manual labour and data updates). The technologies involved in linked data are rather simple, but can be a bit puzzling to developers used to other types of data management systems and other ways to access and handle data. The presentation Working with data.open.ac.uk, the Linked Data Platform of the Open University (see below) gives an overview of the essential elements needed to work with linked data: the basic principles, content negotiation and URI delivery, RDF and SPARQL. It shows on a number of examples from data.open.ac.uk (reusable in different contexts) how developers can make use of these principles to build applications that benefit from linked data.
Besides the purely technical view, it is also important to understand how developers engage with linked data; how they learn to get around the initial frustration caused by a new technology; and how they can start building interesting examples that do more than reproducing what could already be done with the data management system in place. In Putting Linked Data to Work – A Developer’s Perspective, Liam Green-Hughes explains how he went on to learn the basis of linked data-based application development and to build a number of applications where the concepts and principles of linked data are put in practice. This post provides a very interesting view into the kind of efforts that is required to learn linked data from a developer’s point of view, and what mindset is needed: “the realisation that I should just stop worrying about the terminology and get on with using the data.”
Link: Working with data.open.ac.uk, the Linked Data Platform of the Open University
Link: Putting Linked Data to Work – A Developer’s Perspective
Knowing what can be done with linked data
One of the difficulties with linked data and its use is that it takes great efforts to understand what can be done with a given dataset. Indeed, contrary to a relational database, the schema (vocabularies) used does not give much indication regarding the content of the data, and the way the data can be employed. To alleviate this issue, we provided on the LUCERO blog an evolving list of example SPARQL queries that can be used on data.open.ac.uk. These queries are of course specific to our data, but provide examples of the use of various constructs in SPARQL that can be adapted to other domains. It is also interesting to note that these queries were collected using a community mechanism, encouraging developers and users of data.open.ac.uk to post their queries on Twitter using a special hashtag (#queryou) and collecting the most interesting ones.
We also developed a more generic and automatic approach to publicise linked datasets in terms of what can be done with them. As part of KMi’s research work in the area of linked data and the Semantic Web, we developed a tool called whatoask that can extract from a linked dataset the questions it is good at answering. The (rather complex) process is fully automatic and leads to an interface where questions to the considered datasets can be navigated together with their answers, more general and more specific questions. As described in the post What to ask linked data, we applied this tool on three of the data.open.ac.uk datasets, with very interesting results.
Link: example SPARQL queries
Link: What to ask linked data
Example applications
Of course, there is no better way to understand what can be achieved with linked data than to look at existing applications that demonstrate clearly its benefits. data.open.ac.uk provides a page dedicated to the applications that have been developed on top of it. Providing such example applications, preferably with source code, is a perfect way to get developers to understand and learn about the different aspects involved. Each application illustrates a particular quality of or difficulty with linked data and provides useful functionalities on top of such aggregated information, with minimal effort.
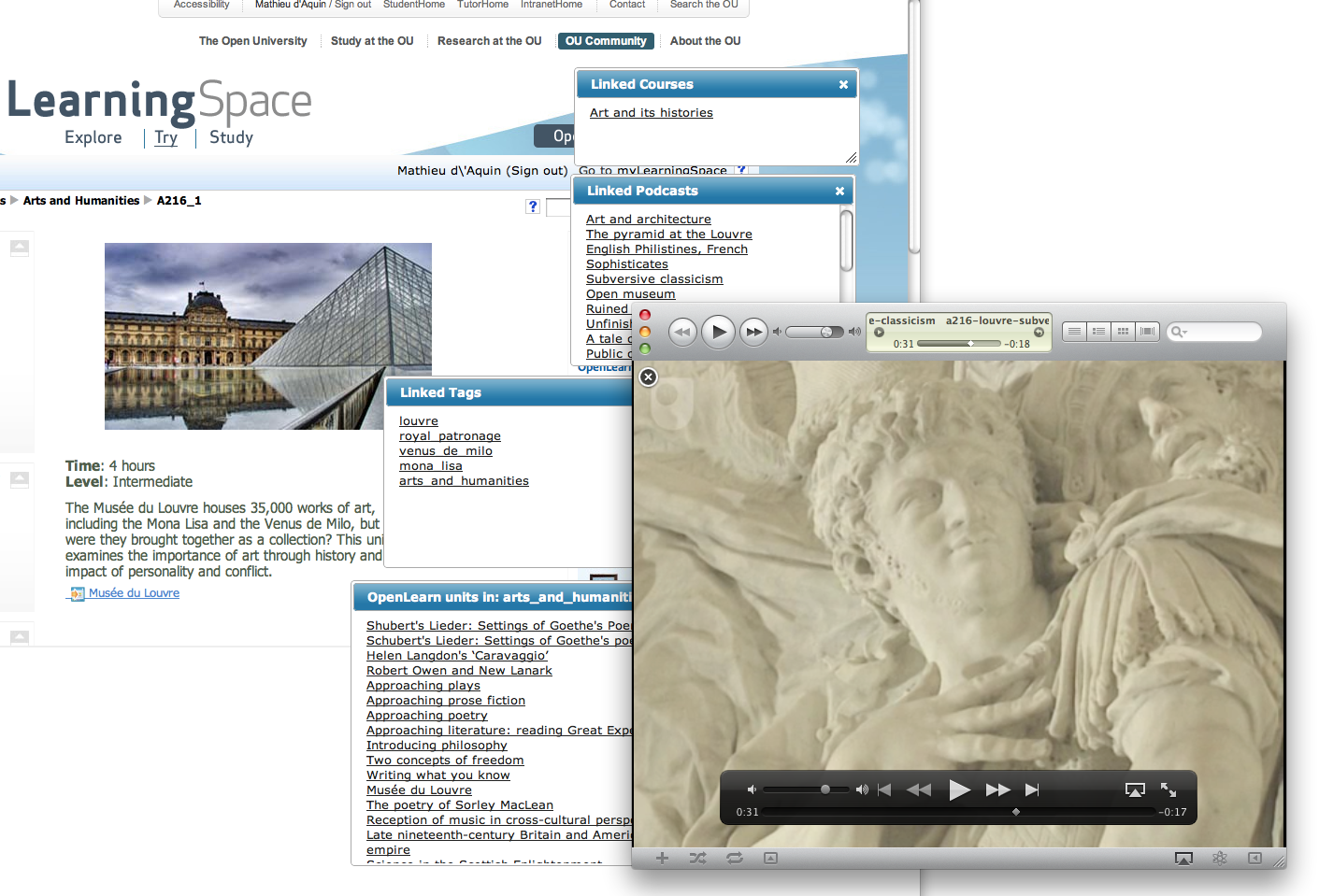
For example, Fouad Zablith developed a small application that connects an OpenLearn unit online to the relevant course at the Open University, to podcasts that talk about the same topic and to other OpenLearn Units that have been annotated with the same tags (see below). In order to realise such an application without linked data would have required integrating data from at least three different systems, each having their own format, modelling, access modes, etc.
In some cases, the goal of an application making use of linked data can actually be to contribute to the data through user engagement. Indeed, when we obtained data from our estate department regarding the buildings and spaces in the Open University’s main campus (in Milton Keynes) and in the 13 regional centers, we got quite excited. The data contain details of the buildings and surroundings of the buildings (car parks, etc.) with their addresses, floors, spaces, images, etc. However, these data were not very well connected. We therefore decided to build an application to not only use these data, but also create some of these missing relations, and specially, to allow OU users to connect to the data.
The application is called wayOU, for “where are you in the OU?”. It can be used to “check-in” at specific locations indicating the “reason” for attending these locations, to keep track of the different places where the user has been, declare the current location as his / her workplace, as well as to connect to their network at the Open University, in terms of the people they share activities with. The source code of the application provides a good basis to learn how to use and create linked data on a mobile platform. It is also worth noticing that wayOU won the Best Demo Award at the Extended Semantic Web Conference 2011
Another example showing how linked data can be used to put together, in a meaningful way, data from very different sources is the application we built as a demonstrator using the Reading Experience Database (see this post on the LUCERO blog). The idea here is that there is a core of institutionally created data, used by researchers to answer questions related to the connections between people, locations and situation, and what they read across time. Through linked data, it is possible to connect such information, previously seating in an isolated database, with other sources of information, enriching the core research data with data for example coming from DBpedia, concerning the people, places and books involved. In addition to opening up the research data with new entry points and new, mostly unintended uses, this has the potential to make emerge new research questions that couldn’t be envisioned before.

Link: data.open.ac.uk applications page
Link: OpenLearn Liked Data application
Link: The wayOU app
Link: Source code of wayOU
Link: Application with the Reading Experience Database
Conclusion
There is no magic formula: deploying linked data in a large institution requires time, skills and efforts. We hope however that Tabloid, the toolkit described above through many links and resources, can provide a good entry point and sufficient help to people interested in getting involved with linked data. Of course, many things still need to be finalized, and other resources should be included. We expect this toolkit to evolve with usage, and with the increased experience in publishing and consuming linked data from the growing number of institutions now engaging with linked data.
Pingback
by Final Product Post: Tabloid « The LUCERO Project
01 Jul 2011 at 18:10
[...] HomeAboutWhat is linked data?data.open.ac.ukTabloid [...]